分布式协调服务ZooKeeper与数据处理服务的理论与实践
随着大数据技术的快速发展,分布式系统已成为处理海量数据的核心架构。在众多分布式技术中,ZooKeeper作为分布式协调服务的关键组件,与数据处理服务紧密协作,为大规模数据应用提供了可靠的保障。本文将结合理论与实践,探讨ZooKeeper在分布式环境中的作用及其与数据处理服务的关系。
一、ZooKeeper的核心概念与功能
ZooKeeper是一个开源的分布式协调服务,由Apache基金会维护。它通过简单的数据模型和高效的协议,为分布式应用提供一致性、可靠性和协调能力。其核心功能包括:
- 配置管理:集中存储和管理分布式系统的配置信息,实现动态更新。
- 命名服务:提供分布式系统中的节点注册与发现机制。
- 分布式锁:支持互斥锁和读写锁,确保资源访问的互斥性。
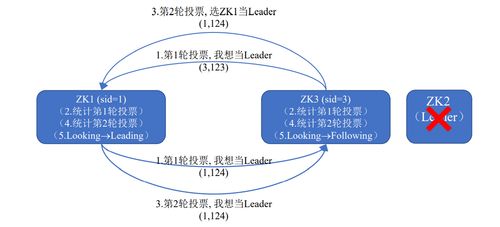
- 集群管理:监控节点状态,实现故障检测和主节点选举。
在实践层面,ZooKeeper采用树形数据模型(ZNode),每个节点可存储少量数据(通常不超过1MB),并通过ZAB(ZooKeeper Atomic Broadcast)协议保证数据一致性。例如,在Hadoop生态中,ZooKeeper被用于HBase的主节点选举和RegionServer状态管理。
二、ZooKeeper与数据处理服务的协同机制
数据处理服务(如Apache Kafka、Apache Flink等)依赖ZooKeeper实现分布式协调。具体协同方式包括:
- 元数据管理:ZooKeeper存储数据分片、任务分配等元数据,确保处理节点间信息同步。
- 故障恢复:通过临时节点监控处理节点存活状态,实现自动故障转移。
- 流量控制:协调数据生产者与消费者的速率,避免系统过载。
以Kafka为例,其依赖ZooKeeper管理Broker注册、主题分区信息和消费者偏移量。当Broker故障时,ZooKeeper会触发重平衡机制,重新分配分区至健康节点。
三、实践案例与优化策略
在实际部署中,需关注ZooKeeper的性能与可靠性:
- 集群部署:建议采用奇数个节点(如3或5)组成集群,通过多数投票机制避免脑裂问题。
- 数据持久化:配置合理的快照与事务日志清理策略,防止磁盘溢出。
- 监控告警:通过四字命令(如stat、ruok)或JMX接口实时监控集群状态。
对于高并发场景,可通过以下方式优化:
- 减少Watcher数量:避免过多监听器导致性能下降。
- 使用Curator框架:简化ZooKeeper客户端编程,提供重试、缓存等高级功能。
四、未来发展趋势
随着云原生技术普及,Etcd、Consul等新兴协调服务逐渐兴起,但ZooKeeper在成熟度和生态集成方面仍具优势。ZooKeeper将更多与容器化、服务网格技术结合,为数据处理服务提供更轻量级的协调方案。
ZooKeeper作为分布式系统的“基石”,通过与数据处理服务的深度集成,确保了大数据应用的可靠运行。开发者需深入理解其原理,并结合实际场景设计合理的架构,方能充分发挥分布式系统的潜力。
如若转载,请注明出处:http://www.jumeiguang.com/product/37.html
更新时间:2025-11-28 07:10:04